2008 has been an exciting year for document format standards. 2009 will, I predict, be rather more boring.
This at least is the conclusion I reached after attending the recent DII workshop organised by Microsoft – and if I say the event was boring I merely mean that we can confidently expect document formats to stop being the at the centre of a spectator sport, and start returning to the land of techies and standards wonks. Boring, but reassuringly so; for while the more slashdotty spectators may prefer the ya-boo exchanges that characterised 2008, for us techies and standards wonks, boring is good – even … exciting.
Boring includes discussion of such topics as:
- The effect of hyphenation dictionaries and justification algorithms on line breaking, and the impact of these considerations on achieving reproducible documents across implementations
- How to decide what the chief document archetypes were for spreadsheets, word-processing documents and presentations
- The distinction between an erratum and an amendment for an IEC/ISO standard
- How to assemble and administer a collection of representative documents for assessing implementation conformance
- How to validate the semantic constraints inherent in an OOXML document
- The trade-off between format-specific and generic document APIs
- How to facilitate server-side document generation
- The trade-off between user convenience and standards adherence
- The quirks of string sharing in Excel
- How to document the implementation decisions an application makes which imposing further constraints on the underlying XML
- How to re-purpose legacy Authorware training materials into OOXML
All good solid stuff, laying the groundwork for the people who really matter in this process (and who perhaps have too often been overlooked) – the end users. Doug Mahugh has a further write-up and links to the presentations on his blog.
Granted, a few eyebrows were raising during one presentation (which has not appeared among the others) which gave a startling frank overview of the challenges Microsoft are anticipating in implementing ISO/IEC 29500, from sucky performance in the deserialision code in PowerPoint, to dumb mistakes in Ecma 376, to coping with the fact that under certain circumstances Office 2007 emits content which is invalid against the Ecma 376 schemas.
I found this last revelation truly heartening – Microsoft did not need to make it, and to date (so far as I am aware) nobody has “caught” Office 2007 emitting invalid XML content. Yet here was MS ’fessing up and asking about ways they could stop it happening in future. All software companies (not just Microsoft) need to have a plain-dealing up-front approach to publicising problems. Such an approach has benefitted the security landscape and will have big benefits for document processing and conformance (and yes, for interoperability too). It is good to see the seeds of such a mature approach – I look forward to seeing Microsoft make this information public soon, and to something equivalent starting up for non-Microsoft ODF implementers too, bearing in mind that (with apologies to Alexander Pope):
Whoever thinks a bug-free app to see,
Thinks what n'er was, nor is, nor e'er shall be.
So, Talking of Bugs and ODF …
ODF Table Test
I had prepared a moderately hard table rendering test to take to Redmond, reasoning that table rendering is a fair indicator of the state of a layout engine beyond a basic “text and headings” level. To create this test document at home perform the following steps:
- Create a 5x5 Table
- Number the cells starting at the top left and moving left-to-right, top-to-bottom until you reach number 25 at the bottom right
- Merge consecutive cells to achieve the result below (note I have also coloured the merged cells to make it easier to see what has happened).
Et voila, a table rendering test. Here is that table displayed in OpenOffice 2.4 (click to enlarge):
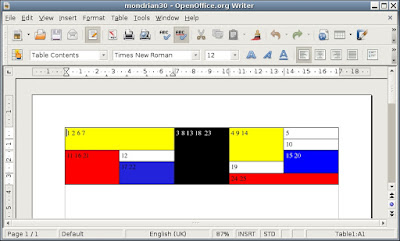
Now, let us see how OpenOffice’s version of the table opens with the SP2 beta for Word 2007:
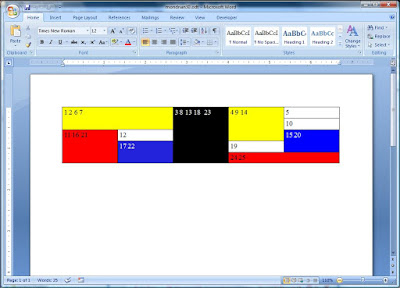
Good – on the face of it, a mini triumph for interoperability. For comparison, I also tried to open the document with Google Docs:
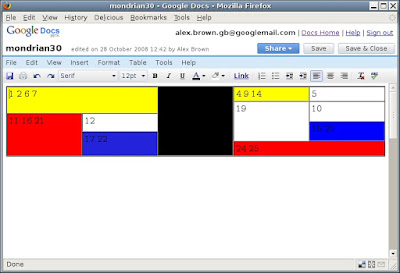
Hmm – notice the different rendering here. Most obviously, the yellow cell which combines the original cells 4, 9 and 14 does not span downward, whereas that is what wanted to achieve when we created the table.
Looking at the ODF source, everything appears to be in order. The top-most spanned cell is marked-up as follows
<table:table-cell table:style-name="Table1.A1"
table:number-rows-spanned="3" office:value-type="string">
<text:p text:style-name="Table_20_Contents">4 9 14</text:p>
</table:table-cell>
The number-rows-spanned="3" attribute specified the row-spanning correctly, and the spanned-into cells (not shown) are properly marked-up with <table:covered-table-cell/> elements as the ODF spec suggests. (Interesting note: at no point is the ODF spec explicit that row spanning operations apply downwards – I have come across XML table models – Arbortext’s for example - which specify that spans apply upwards, and it is theoretically open for an ODF implementation to chose to do that too. So much for interoperability!)
So I think here we can reasonably point the finger at Google Docs and say that its table renderer is faulty – these guys need to catch up with OpenOffice and Microsoft.
Curiously, opening this test file with an early version of OpenOffice.org (1.1.5) gives the same rendering error as today’s Google docs:
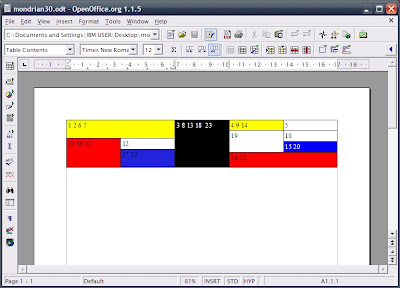
And so we have seen a minor failure of interoperability. Of course it might not be so minor if these documents contained more important information (financial or medical data, e.g.) and not just pretty colours. This test however, just scratches the surface – for a more thoroughgoing examination of the poor state of ODF interoperability, readers can turn to the recent study by Shah and Kesan (and no, OOXML does not emerge hugely better from this either).
Looking Forward
Achieving interoperability appears to be the new focus for both the developers and standardisers working on document formats. For ODF, OASIS has the new Open Document Format Interoperability and Conformance (OIC) TC to advance work in this area. Microsoft is not currently represented here, and it is to be hoped they might soon overcome their shyness and participate. After all, when Office 2007 SP2 ships, Microsoft Office will quickly become the predominant ODF implementation, and it is important everybody works together to ensure they improve conformance and interoperability, and that where the ODF specification is insufficient for this, feedback is returned to ODF’s custodians.
Microsoft too are evidently thinking about interoperability and several presentations at the DII workshop were concerned with work to build a repository of representative Office documents to provide input into conformance and interoperability testing processes. Such an initiative is useful, though ideally it should take place under the aegis of a standards committee (e.g. OASIS or SC 34 / WG 4), to parallel the activities taking place for ODF.
There was indeed, plenty of corridor discussion about how the future standards arrangements for ODF and OOXML might be best organized. I was particularly pleased to meet Dennis Hamilton (aka Orcmid), a member of the OASIS ODF TC and secretary to the OIC TC there – and we had plenty of constructive discussions about the how the current impasse in ODF maintenance might best be negotiated. However, the immediate solution to that particular problem now lies above the reach of mere committee members like us; it is between the lawyers and officials of OASIS and JTC 1.
R&R
After the workshop finished, there was time before my midnight flight for some R&R. Doug Mahugh was good enough to indulge my confession to being a Frasier fan and give me a tour of Seattle (where he grew up). It was good too to take a break from document formats and discuss less controversial topics like the US election, the identity of Mini-Microsoft, and Kirk/Spock porn!

Me being shown Seattle culture (photo: Doug Mahugh)
[UPDATE: Jesper Lund Stocholm has also just blogged on the topic of ODF support in MS Office — highly recommended.]
[UPDATE 2: wifely perspective.]